最近在使用 Node 的子进程模块实现一些功能,对相关知识进行了一个系统的学习总结,这篇文章将会简要介绍我总结的 Node 中和进程有关的内容。包括:进程和线程、Node 的单线程的真正含义、创建进程的三种方法、进程间通信、进程以及信号量。有不当之处欢迎提出,一起交流。
进程及线程
在真正开始介绍 Node 中的 child_process 模块之前,先来简要介绍一些操作系统的基础知识。
我们首先从操作系统的任务调度开始。
现代的操作系统一般都是“多任务”的,可以同时运行多个任务。比如:我们可以一边听歌一边敲代码一边下载小电影,还有一些任务在后台悄悄同时运行。但是当我们只有一个 CPU 时,操作系统又是怎么做到“多任务”的?
操作系统会进行调度(任务切换)来实现多任务:也就是一个任务执行一段时间后被暂停,下一个任务再执行一段时间,然后不断循环执行下去,这样每个任务都能得到交替执行。虽然是交替执行,但是CPU 执行效率很高,在各个任务间快速切换,给我们的感觉就是多个任务在“同时运行”,也就是我们说的“多任务”。
上面的调度并不是真正的并行执行,真正的并行执行多个任务实际上只能在多核 CPU 上实现。但是,由于任务数量肯定会远远多于 CPU 的核心数量,操作系统也会自动把很多任务轮流调度到每个 CPU 上执行。
一个任务实际上就是一个进程(Process),它是操作系统进行资源分配和调度的最小单位,是应用程序运行的载体,有自己独立的内存空间。
但是有些进程并不满足同时干一件事,比如:播放器播放小电影的时候,它可以同时播放视频、音频。
在一个进程内要同时干多件事就需要运行多个“子任务”,这些进程内的子任务就是线程(Thread),它是程序执行的最小单位,一个进程可以有一个或多个线程,各个线程间可以共享进程的内存空间。
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。当然,进程可以有多个线程,多个线程可以“同时执行”,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。但是,线程间的上下文切换要比进程的上下文切换开销小,也快得多。
我们可以通过资源管理器(windows)或者活动监视器(mac)来查看我们系统里的进程和线程,如下图是活动监视器的截图:

当然也可以通过 ps、top 等命令来查看进程信息,可以参考:http://www.imooc.com/article/1071。
让我们总结下:
- 线程是程序执行的最小单元,进程是任务调度的最小单元
- 一个进程由一个或多个线程组成(至少一个),线程间可以共享进程的内存空间,进程间互相独立(有各自的内存空间)
- 操作系统使用 CPU 时间分片来调度进程、线程的执行,从而实现多任务
- 线程间的切换比进程间切换开销小
关于 Node 的单线程
我们知道 Node 类似于浏览器里面的 JavaScript,是单线程的。那我们现在需要理解 Node 的单线程到底是什么意思?
这里说的单线程是指我们所编写的代码运行在单线程上,实际上 Node 并不是真的“单线程”。
当我们执行 node app.js 时启动了一个进程,但是这个进程并不是只有一个线程,而是同时创建了很多个线程(比如:异步 IO 需要的一些 IO 线程)。如下图所示(编号为 92347 的进程一共有 5 个线程):
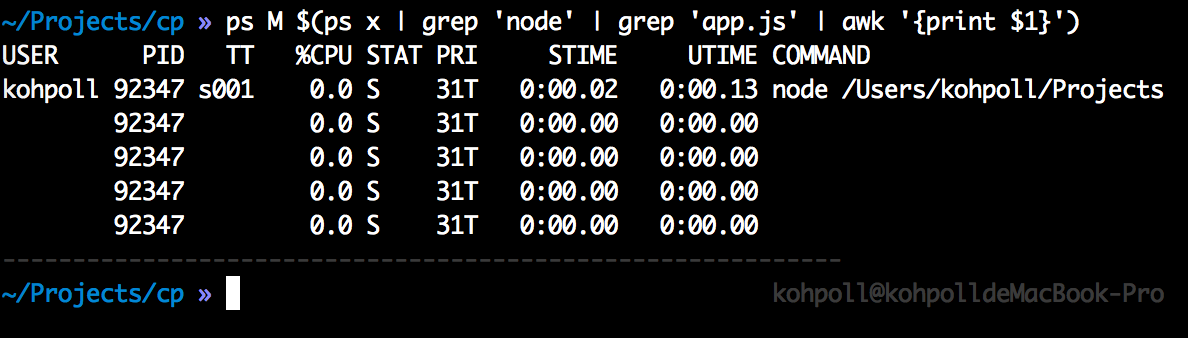
但是,仍然只有一个线程会运行我们编写的代码。这就是 Node 单线程的含义。
Node 实际上从语言层面就不支持创建线程,我们只有能力创建进程。这让我们的程序状态单一,不用在意状态同步、死锁、上下文切换开销等等多线程编程中的头疼问题。当然,我们可以通过进程间的通信来共享一些“状态”,但并不是线程间共享的那种状态。
单线程也会带来一些问题:
- 无法利用多核 CPU(只能获得一个 CPU 的时间分片)
- 错误会引起整个应用退出(整个应用就一个进程,挂了就挂了)
- 大量计算长时间占用 CPU,导致阻塞线程内其他操作(异步 IO 发不出调用,已完成的异步 IO 回调不能及时执行)
这些问题实际上都有对应的解决方案。我们会使用 Master-Worker 的管理方式来创建和管理多个工作进程(工作进程数量一般会等于系统 CPU 的核心数量),保证应用能够充分利用多核 CPU,同时在发生错误时可以优雅退出和自动重启(比如 recluster 模块)。我们会新创建一个独立进程来进行耗时的计算,然后将计算结果传回给主线程。它们本质上都在使用 Node 提供的子进程功能。
进程创建简明指南
在 Node 中,大体上有三种创建进程的方法:
- exec / execFile
- spawn
- fork
exec / execFile
exec(command, options, callback) 和 execFile(file, args, options, callback) 比较类似,会使用一个 Buffer 来存储进程执行后的标准输出结果,我们可以一次性在 callback 里面获取到。不太适合输出数据量大的场景。
需要注意的是,exec 会首先创建一个新的 shell 进程出来,然后执行 command;execFile 则是直接将可执行的 file 创建为新进程执行。所以,execfile 会比 exec 高效一些。
exec 比较适合用来执行 shell 命令,然后获取输出(比如:exec('ps aux | grep "node"')),但是 execFile 却没办法这么用,因为它实际上只接受一个可执行的命令,然后执行(没法使用 shell 里面的管道之类的东西)。
1 | // child.js |
1 | // parent.js |
1 | // parent.js |
两个方法还可以传递一些配置项,如下所示:
1 | { |
spawn
spawn(command, args, options) 适合用在进程的输入、输出数据量比较大的情况(因为它支持 stream 的使用方式),可以用于任何命令。
1 | // child.js |
1 | // parent.js |
我们可以执行 cat bigdata.txt | node parent.js 来进行测试,bigdata.txt 文件的内容将被打印到终端。
spawn 方法的配置(options)如下:
1 | { |
我们这里主要介绍下 detached 和 stdio 这两个配置。
stdio
stdio 用来配置子进程和父进程之间的 IO 通道,可以传递一个数组或者字符串。比如,['pipe', 'pipe', 'pipe'],分别配置:标准输入、标准输出、标准错误。如果传递字符串,则三者将被配置成一样的值。我们简要介绍其中三个可以取的值:
- pipe(默认):父子进程间建立 pipe 通道,可以通过 stream 的方式来操作 IO
- inherit:子进程直接使用父进程的 IO
- ignore:不建立 pipe 通道,不能 pipe、不能监听 data 事件、IO 全被忽略
比如上面的代码如果改写成下面这样,效果完全一样(子进程直接使用了父进程的 IO):
1 | const p = child_process.spawn( |
detached
detached 配置主要用来创建常驻的“后台”进程,比如下面的代码:
1 | // child.js |
1 | // parent.js |
这样就实现了常驻的后台进程,父进程退出了、shell 关掉了,子进程都会一直运行,直到手动将它 kill 掉。
虽然在子进程里面,我们每隔 1s 就输出了一个信息,但是其实根本就看不到。如果我们想要记录子进程的输出的话,可以给它指定一个单独的 IO(不能和父进程建立 IO 通道,否则没法独立运行):
1 | const out = fs.openSync('./out.log', 'a'); |
fork
fork(modulePath, args, options) 实际上是 spawn 的一个“特例”,会创建一个新的 V8 实例,新创建的进程只能用来运行 Node 脚本,不能运行其他命令。并且会在父子进程间建立 IPC 通道,从而实现进程间通信。
1 | // child.js |
1 | // parent.js |
上面代码的效果和使用 spawn 并配置 stdio: inherit 的效果是一致的。我们看下该方法的配置(options)就知道原因了:
1 | { |
总结
- exec / execFile:使用 Buffer 来存储进程的输出,可以在回调里面获取输出结果,不太适合数据量大的情况;可以执行任何命令;不创建 V8 实例
- spawn:支持 stream 方式操作输入输出,适合数据量大的情况;可以执行任何命令;不创建 V8 实例;可以创建常驻的后台进程
- fork:spawn 的一个特例;只能执行 Node 脚本;会创建一个 V8 实例;会建立父子进程的 IPC 通道,能够进行通信
进程间通信
我们上面介绍的三种创建子进程的方法都会返回一个 ChildProcess 类的实例,它其实继承于 EventEmitter。
我们上面已经看到了一些用法:
- 获取进程的
pid - 监听
exit等事件(其他事件有:error、close等) - 访问
stdin、stdout、stderr属性(这些属性又是Stream的实例,可以像操作 stream 一样进行操作)
这部分我们简要介绍下进程间通信的方法,主要就是通过收发消息来实现。
实际上默认情况下,只有 fork 出的子进程才能和父进程收发消息,因为 fork 会建立父子进程的 IPC 通道,其他方法并不会建立这种通道。
1 | // child.js |
1 | // parent.js |
通过监听 message 事件和调用 send 方法,我们就可以在父子进程间进行通信了。至于通信协议,我们可以自己设计或者直接使用 JSON,毕竟传递的都是一推字符串,很易用。
进程及信号量
除了我们会和进程通信外,实际上操作系统也会给进程发送一种叫做信号量的“消息”来告知进程某些事件发生了。一般会使用 kill [sid] [pid] 命令来发送信号量,一些常见的信号量如下:
| kill [sid] [pid] | process.on(evt) | 说明 |
|---|---|---|
| kill -1 / kill -HUP | process.on(‘SIGHUP’) | 一般表示进程需要重新加载配置 |
| kill -2 / kill -SIGINT / ctrl+c | process.on(‘SIGINT’) | 退出进程 |
| kill -15 / kill -TERM | process.on(‘SIGTERM’) | 停止进程(kill 的默认信号) |
| kill -9 / kill -KILL | 监听不到 | kernel 直接停掉进程,并且不通知进程 |
实际上 process 还可以监听 exit 事件,监听 exit 事件和监听信号量事件是不一样的。exit 事件只有在执行 process.exit() 或者进程结束时才会触发。
所以,一个“优雅”的进程一般会绑定 exit、SIGINT、SIGTERM 事件,在 exit 事件中处理进程的清理工作,然后在 SIGTERM、SIGINT 事件中调用 process.exit() 来让进程真正退出。(如果你想耍流氓,可以绑定 SIGTERM、SIGINT 事件,然后啥也不做,这样除非使用 kill -9,你的进程将永远不会退出……)
除了通过 kill 命令发送信号量,我们也可以使用子进程的 .kill(sig) 方法来发送信号,比如:p.kill('SIGINT');或者 process 的process.kill(pid, 'SIGINT')。
参考资料
- http://blog.csdn.net/luoweifu/article/details/46595285
- https://nodejs.org/dist/latest-v4.x/docs/api/child_process.html
- https://nodejs.org/dist/latest-v4.x/docs/api/process.html
- http://www.imooc.com/article/1071
- https://meinit.nl/the-3-most-important-kill-signals-on-the-linux-unix-command-line
- 《深入浅出 Node.js》
本文采用 知识共享署名 3.0 中国大陆许可协议,可自由转载、引用,但需署名作者且注明文章出处 。